00-1010有两种常见的多维查询场景,即:
具有多个过滤条件的列表查询不包含具有子数据库和子表列的其他维度查询。以上需求场景都很难实现,更别说模糊查询和全文检索了。
基于楼主的经验和知识,下面介绍初级方案和高级方案(关于ElasticSearch)。大多数情况下,建议使用ElasticSearch实现多维查询。着急的读者可以直接跳转到“高级方案:在现有系统中加入ElasticSearch”。
00-1010
背景
这是为了实现多种过滤条件的列表查询。
00-1010很简单。读写不一致时间短:取决于数据库主从同步延迟,一般为毫秒级。
初级方案
非常有限:除非过滤条件固定,否则很难应对后续过滤条件的添加或修改。如果每次都需要新的过滤查询字段,就会增加索引,最终导致索引过大,影响性能。于是,就有了经典的一幕:产品要求要支持一个新领域的过滤查询,开发反馈说做不到
00-1010更好的方法是异构化多个数据。
例如,终端C按用户维度查询,终端B按商店维度查询,如果有供应商,则按供应商维度查询。一个数据库只能按照一个维度进行分类。
00-1010的好处是非常简单。
1、根据常见查询场景,增加相应字段的组合索引
跨数据库写入存在一致性问题(除非不同维度的表使用共同的子数据库和事务写入),性能较低,无法灵活支持更多其他维度的查询。
优点
通过Canal同步数据,异构多维数据源。详情请参考上一篇文章:架构师必备:使用Canal实现异步解耦架构。
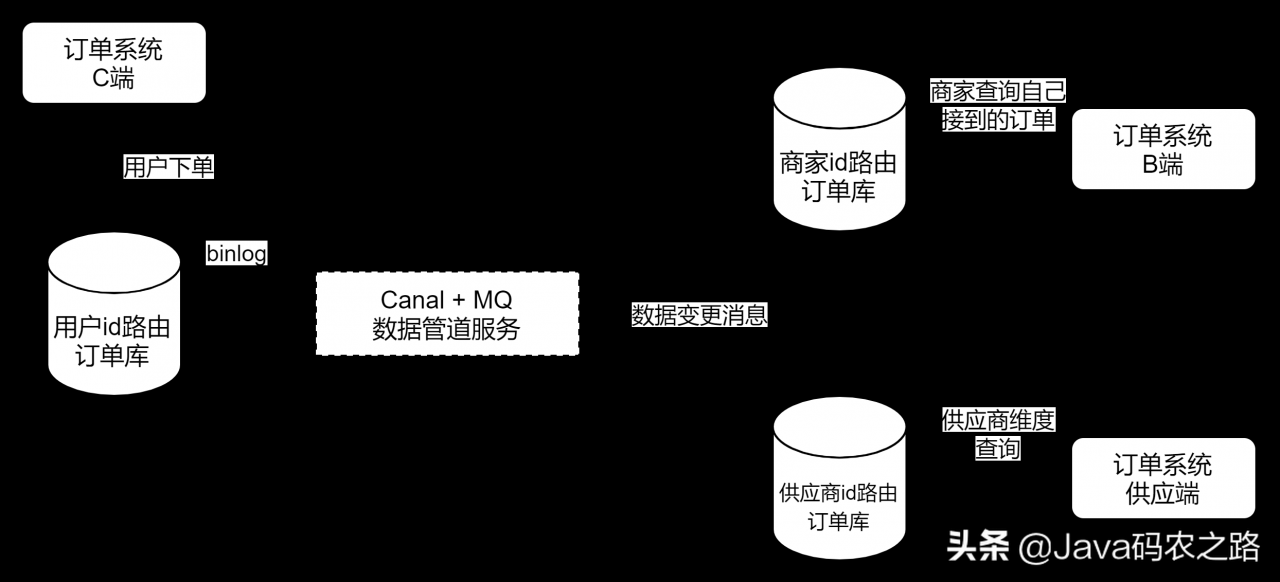

优点:更优雅,不需要改变程序的主流程。
缺点
仍然不能解决不断变化的需求,也不可能为了支持新的维度而异构化一个新的数据。
2、异构出多份数据
(1)程序写入多个数据源
现有系统普遍使用MySQL数据库,需要引入ES来增强系统的多维查询功能。
MySQL继续承担实时的读写请求和事务操作,es则承担近实时的多维查询请求。ES可以支持100,000个qp(取决于节点、切片和拷贝的数量)。
需要注意的是,同步数据到ES是秒级延迟(主要花在索引刷新上),而查询已经进入索引的文档是几毫秒到几百毫秒的量级。
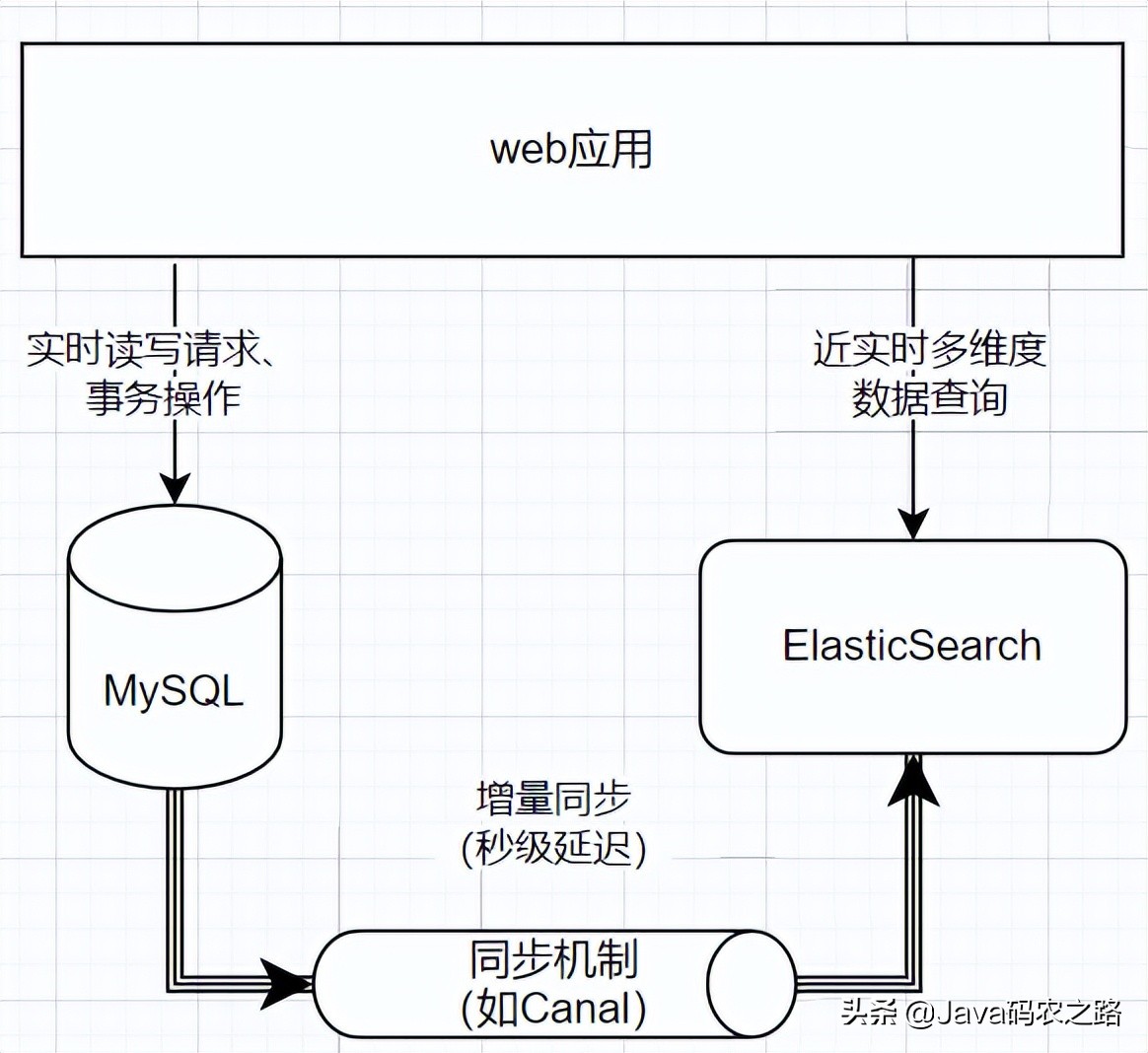
00-1010将MySQL中的数据导入ES需要一个同步机制。主要流程如下:
提前定义ES索引的映射配置,而不是依赖ES自动生成映射。初始全导入和后续增量导入:Canal MQ数据管道同步,不需要或只需要少量代码。数据过滤:不需要检索的字段不导入,索引大学减少,性能提升。数据扁平化:如果数据库中有json字段列,需要从中提取业务字段,避免字段的嵌套类型,提高性能。
88″ img_height=”876″ alt=”架构师必备:多维度查询的最佳实践” inline=”0″>
查询数据
从ES 8.x版本开始,建议使用Java api client,并且要Java 8及以上环境,因为可使用各种lambda函数,来提高代码可读性优点是新客户端与server代码完全耦合(相比于原Java transport client,在8.x版本已废弃),并且API风格与http rest api很接近(相比于原Java rest client,在8.x版本已废弃),只要熟练掌握http json请求体写法,即可快速上手。底层使用的还是原来的low level rest client,实现了http长连接、访问ES各节点的负载均衡、故障转移,最底层依赖的是apache http async client。ES 7.x版本及以下,或使用Java 7及以下,建议升级,否则就只能继续用high level rest client。
代码示例如下(含详细注释):
public class EsClientDemo { // demo演示:创建client,然后搜索 public void createClientAndSearch() throws Exception { // 创建底层的low level rest client,连接ES节点的9200端口 RestClient restClient = RestClient.builder( new HttpHost("localhost", 9200)).build(); // 创建transport类,传入底层的low level rest client,和json解析器 ElasticsearchTransport transport = new RestClientTransport( restClient, new JacksonJsonpMapper()); // 创建核心client类,后续操作都围绕此对象 ElasticsearchClient esClient = new ElasticsearchClient(transport); // 多条件搜索 // fluent API风格,并且使用lambda函数提高代码可读性,可以看出Java api client的语法,同http json请求体非常相似 String searchText = "bike"; String brand = "brandNew"; double maxPrice = 1000; // 根据商品名称,做match全文检索查询 Query byName = MatchQuery.of(m -> m .field("name") .query(searchText) )._toQuery(); // 根据品牌,做term精确查询 Query byBrand = new Query.Builder() .term(t -> t .field("brand") .value(v -> v.stringValue(brand)) ).build(); // 根据价格,做range范围查询 Query byMaxPrice = RangeQuery.of(r -> r .field("price") .lte(JsonData.of(maxPrice)) )._toQuery(); // 调用核心client,做查询 SearchResponse<Product> response = esClient.search(s -> s .index("products") // 指定ES索引 .query(q -> q // 指定查询DSL .bool(b -> b // 多条件must组合,必须同时满足 .must(byName) .must(byBrand) .must(byMaxPrice) ) ), Product.class ); // 遍历命中结果 List<Hit<Product>> hits = response.hits().hits(); for (Hit<Product> hit: hits) { Product product = hit.source(); // 通过source获取结果 logger.info("Found product " + product.getName() + ", score " + hit.score()); } }}
可参阅:https://www.elastic.co/guide/en/elasticsearch/client/index.html
数据模型转换
因为既有MySQL,又有ES,所以有2种异构的数据模型。需要在代码中定义2种数据模型,并且实现类型互相转换的工具类。
MySQL数据VOES数据VOMySQL数据VO、ES数据VO互相转换工具业务层BO接口DTO
原理概要
ES之所以比MySQL,能胜任多维度查询、全文检索,是因为底层数据结构不同:
ES倒排索引如果是全文检索字段:会先分词,然后生成 term -> document 的倒排索引,查询时也会把query分词,然后检索出相关的文档。相关度算法如TF-IDF(term frequency–inverse document frequency),取决于:词在该文档中出现的频率(TF,term frequency),越高代表越相关;以及词在所有文档中出现的频率(IDF,inverse document frequency),越高代表越不相关,相当于是一个通用的词,对相关性影响较小。如果是精确值字段:则无需分词,直接把query作为一个整体的term,查询对应文档。因为文档中的所有字段,都生成了倒排索引,所以能处理多维度组合查询MySQL B+树B+树的非叶子节点记录了孩子节点值的范围,而叶子节点记录了真正的一组值,并且在同一层,形成了一个有序链表组合索引需要显式创建:选择需索引的字段、并且顺序是重要的,所以如果待查询的字段不在索引中,就无法高效查询,可能演变为全表扫描(对聚簇索引的叶子节点做一次遍历)
另外简要回顾一下ES的架构要点:
节点分为主节点、数据节点,一个节点上可以有多个分片,分片分为主分片、副本分片,1对多,主分片与副本分片分布在不同的节点,来实现高可用主分片数在创建时,就需要指定,在创建后不能随意更改(如果变化,路由就会出错);而副本分片可以增加,来提高ES集群的查询QPS路由算法:id % 主分片数,如果创建文档时不指定id,则ES会自动生成;一般会传自定义业务id
优点、缺点
优点
支持各字段的多维度组合查询,无惧未来新增字段(主要成本在于新增字段后、重建索引)与现有系统完全解耦,适合架构演进在数据量级上远胜Mysql,最大支持PB级数据的存储和查询
缺点
读写不一致时间在秒级:因为有2个耗时阶段,一是同步阶段将数据从MySQL数据库写入ES,二是ES索引refresh阶段,数据从buffer写入索引后才可查到因此一个trick就是,在写入操作后,前端延迟调用后端的列表查询接口,比如延迟1秒后再展示超高并发下存在瓶颈,存在稳定性问题:目前原生版本支持大约 3-5 万分片,性能已经到达极限,创建索引基本到达 30 秒+ 甚至分钟级。节点数只能到 500 左右基本是极限了。但依然能满足绝大部分场景。数据来源:https://elasticsearch.cn/slides/259#page=30
ES最佳实践
只把需要搜索的数据导入ES,避免索引过大数据扁平化,不用嵌套结构,提高性能合理设置字段类型,预先定义mapping配置,而不依赖ES自动生成mapping精确值的类型指定为keyword(mapping配置),并且使用term查询精确值是指无需进行range范围查询的字段,既可以是字符串,比如书的作者名字,也可以是数值,比如商品id、订单id、图书ISBN编号、枚举值。在使用中,大部分场景是以id类作为精确值避免无路由查询:无路由查询会并发在多个索引上查询、归并排序结果,会使得集群cpu飙升,影响稳定性避免深度分页查询:如有大量数据查询,推荐用scroll滚动查询设置合理的文件系统缓存(filesytem cache)大小,提高性能:因为ES查询的热数据在文件系统缓存中ES分片数在创建后不能随意改动,但是副本数可以随时增加,来提高最大QPS。如果单个分片压力过大,需要扩容。
更进一步
前面提到ES超高并发下存在瓶颈,极端情况下可能遇到OOM,因此超高并发下需要C++实现的专用搜索引擎
例如:
百度:通用搜索引擎,根据文字、图片搜索信息电商垂类:电商专用搜索引擎,比如根据关键词查找商品,或根据品牌、价格筛选商品,可总结为商品的搜索、广告、推荐
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/241199.html